





Introduction
At 2:07 AM, your payment system crashes.
Traffic has spiked from another region. The API can’t handle the load. Transactions start failing. Slack channels light up:
- “Payments Down?”
- “API latency spiking”
- “Anyone On this?”
No one responds. Your email alerts are muted. Slack notifications are off. The monitoring system did its job. It detected the issue. But no one is acting on it.
By the time you wake up and check your phone, there are:
- 200+ Slack images
- Dozens of alert emails
- Multiple missed incident notifications
The system failed, and it failed loudly. By the time the issue is finally resolved, the damage is already done. Lost transactions. Frustrated users. Revenue gone. This isn’t a rare edge case. This is what happens when alerting systems notify, but don’t ensure a response.
Breaking Down The Failure
The incident described earlier isn’t a one-off.
It’s a pattern most SRE teams have encountered at some point.
At first glance, the system appears to be working. Monitoring tools detect anomalies and generate alerts. But the failure happens in what comes next. Most alerting systems rely on passive communication channels such as email or Slack . These channels assume that someone is actively watching or will notice the alert in time.
In reality, that assumption breaks quickly.
- Notifications may be turned off
- The incident may occur outside active working hours
When this happens, alerts are generated, but no one acknowledges them.
At the same time, another issue compounds the problem. Not all alerts are equal, yet many systems treat them that way.
- Alerts that have low priority continue to flow
- Critical alerts get buried in the noise
- There is no clear prioritization or routing
The result is predictable:
The system detects failures, but the response is delayed or missed entirely.
Why Common Alert Setups Fail
There is a common assumption that having a monitoring system in place is enough to ensure reliability. In reality, that is only half the story.
Alerts are configured, notifications are enabled, and on-call schedules are defined. On paper, the system appears complete. In practice, these setups often fail at the exact moment they are needed most.
The issue is not the lack of alerts. Modern systems are highly capable of detecting anomalies and generating notifications in real time. The failure lies in what happens after an alert is triggered.
Most alerting systems rely on passive communication channels and assume that someone is available to notice and respond. That assumption does not hold under real-world conditions.
To understand why, it is important to look at how commonly used alerting methods behave:
Security Risks of Centralised Data
There is a common assumption that having a monitoring system in place is enough to ensure reliability. In reality, that is only half the story.
Alerts are configured, notifications are enabled, and on-call schedules are defined. On paper, the system appears complete. In practice, these setups often fail at the exact moment they are needed most.
The issue is not the lack of alerts. Modern systems are highly capable of detecting anomalies and generating notifications in real time. The failure lies in what happens after an alert is triggered.
Most alerting systems rely on passive communication channels and assume that someone is available to notice and respond. That assumption does not hold under real-world conditions.
To understand why, it is important to look at how commonly used alerting methods behave:
- Email alerts: Easy to ignore and dependent on active checking. If notifications are turned off or the recipient is unavailable, the alert goes unnoticed. Email serves as a record of an incident, not a mechanism for immediate response.
- Slack/Chat alerts: Delivered in high-volume communication channels where critical alerts compete with regular messages. This makes it difficult to distinguish urgency, increasing the risk of alerts being missed or delayed.
- Basic on-call Systems: Assign responsibility, but rely heavily on availability. If the assigned engineer misses the alert, there is often no immediate enforcement of acknowledgement. Escalation, if present, is delayed or manual.
Re-thinking Incident Management
In practise, the assumption breaks down. That is:
- An alert being generated does not guarantee that it is seen.
- An alert being seen does not guarantee that it is acknowledged.
- An alert being acknowledged does not guarantee timely action.
As infrastructure becomes more distributed and systems operate across time zones, relying on passive alerting mechanisms is no longer sufficient. Incident management cannot depend on availability, attention, or manual follow-up.
This is yet another way of saying: “The gap between detection and response is where most incidents escalate.”
The incident response needs to be structured, enforced, and bound by a timeline. This brings us to the lifecycle of alerts:
- Delivery to the responsible individual
- Mandatory acknowledgement within a set timeframe
- Automated escalation if no action is taken
The end goal is not just to detect issues, but to ensure that critical automated escalation occurs if no action is taken. Our workflow is driven by a defined path where, from detection to resolution, there is zero reliance on manual follow-up.
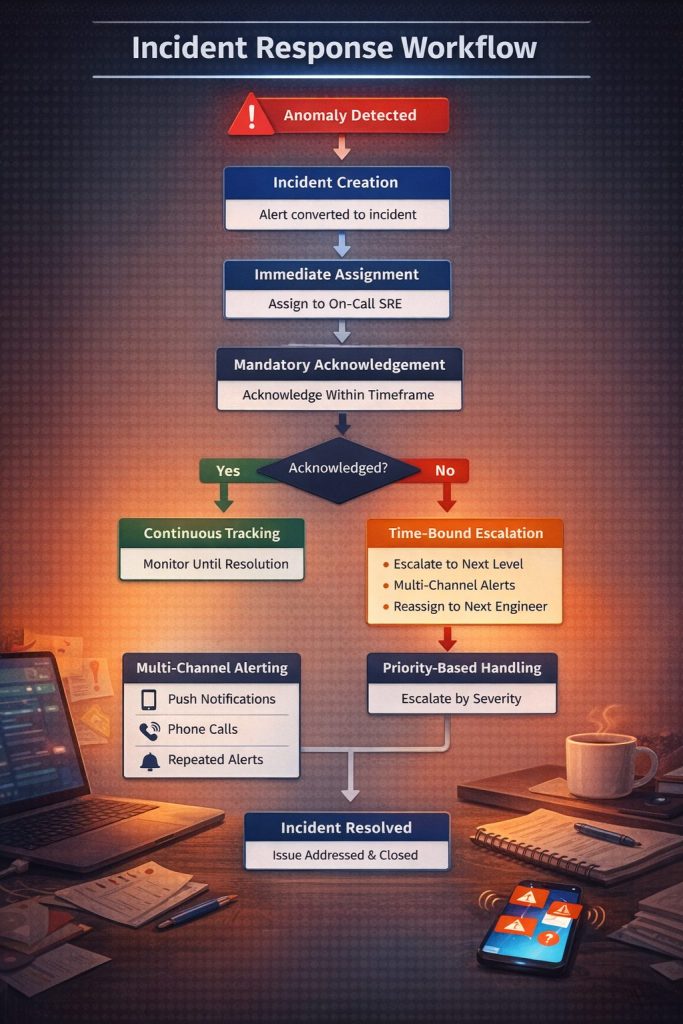
This is a key feature in driving change; for example, this mitigates missed alerts due to passive channels. There is now ambiguity on the ownership of the incident, and also nil delays in solving the issue due to delays caused by manual selection.
By enforcing response at every stage of the incident lifecycle, Innovature ensures that alerts lead to immediate and accountable action. Incidents are acknowledged faster, response times are significantly reduced, and critical issues are far less likely to be missed. This structured approach minimizes system downtime and shifts the focus from simply detecting problems to resolving them without delay.












